Building a Production-Grade LLM Application: A Developer's Journey
As seasoned developers, we’ve witnessed the ebb and flow of numerous tech stacks. From the meteoric rise of MERN to the gradual decline of AngularJS, and the innovative emergence of Jamstack, tech stacks have been the backbone of web development evolution.
Enter the LLM Stack—a cutting-edge tech stack designed to revolutionize how developers build and scale Large Language Model (LLM) applications.
In this blog, we’ll embark on a developer’s journey, exploring the challenges of building a production-grade LLM application and how the LLM Stack provides solutions at each step.
The Challenge: From Simple Idea to Complex Reality
LLM applications are deceptively simple to kickstart, but scaling them unveils a Pandora’s box of challenges:
- Platform Limitations: Traditional stacks struggle with the unique demands of LLM apps.
- Tooling Gaps: Existing tools often fall short in managing LLM-specific workflows.
- Observability Hurdles: Monitoring LLM performance requires specialized solutions.
- Security Concerns: LLMs introduce new vectors for data breaches and prompt injections.
To illustrate this evolution, let’s dive into the story of Alex, a developer tasked with building an internal chatbot for a small business.
Stage 1: Building the Basic Chatbot
Alex starts with a simple goal: create a chatbot to help employees manage their inboxes more efficiently.
Approach:
- Copy and paste the last 10 emails into the LLM’s context.
- Use the LLM to answer employees’ questions based on these emails.
System Prompt:
Here are the last 10 emails in the inbox:
EMAILS: [{
...
}, ...]
Answer the user's questions.
User Input:
What is the status of the order with the ID 123456?
Outcome:
- The chatbot provides quick answers based on recent emails.
- Employees find it helpful for managing immediate queries.
Stage 2: Facing Observability Issues
As the chatbot gains popularity, the company’s API usage surges, leading to unexpected costs.
Challenge:
- API costs skyrocket to $100 a day.
- Lack of visibility into API consumption and performance.
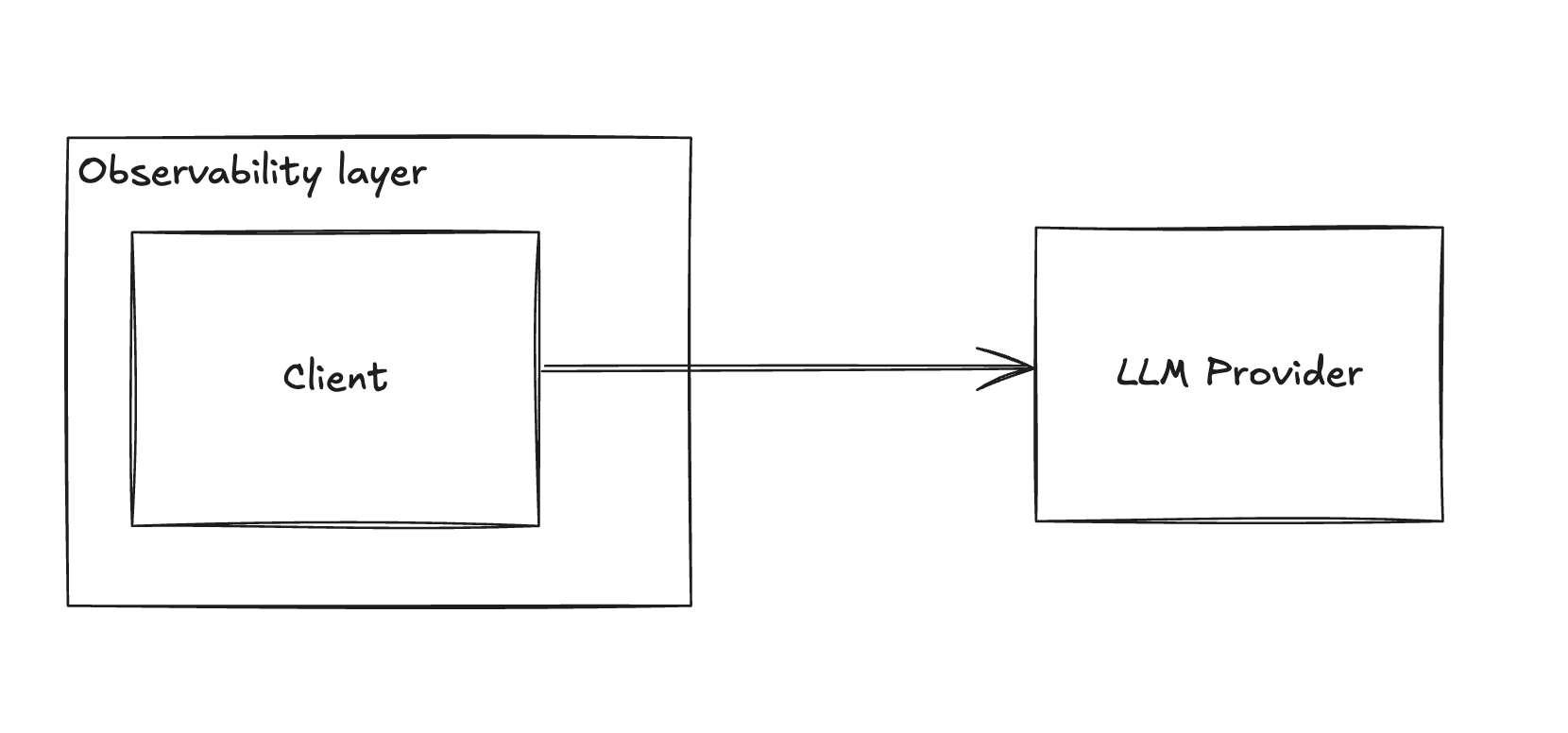
Solution: Implement an Observability Layer
- Integrate tools like Helicone.
- Gain insights into API usage, response times, and error rates.
Benefit:
- Monitor and optimize API calls.
- Identify and fix performance bottlenecks.
Stage 3: Scaling with Vector Databases
Employees begin to report that the chatbot misses important information from older emails.
Challenge:
- The chatbot’s context window is limited to the last 10 emails.
- Inability to access historical data reduces its effectiveness.
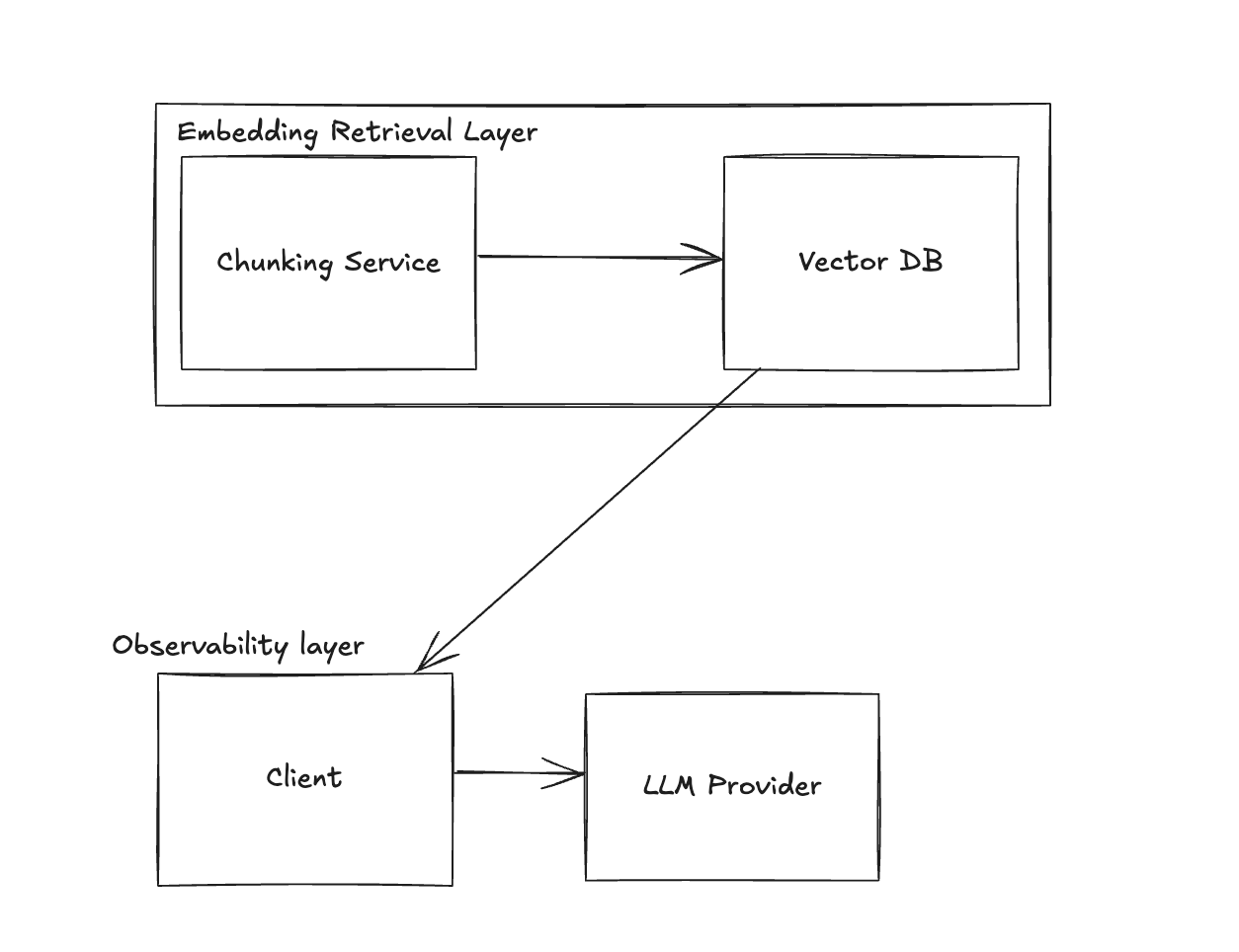
Solution: Introduce a Vector Database
- Use embeddings to store and retrieve all emails.
- Implement a vector database like Pinecone or Vespa.
Action:
- Modify the chatbot to query the vector database for relevant emails based on user queries.
Benefit:
- Access to a broader knowledge base.
- More accurate and comprehensive responses.
Stage 4: Optimizing with a Gateway
With increased usage, performance issues arise, and costs continue to climb.
Challenge:
- Redundant API calls and inefficient load handling.
- Need for rate limiting and caching to manage resources.
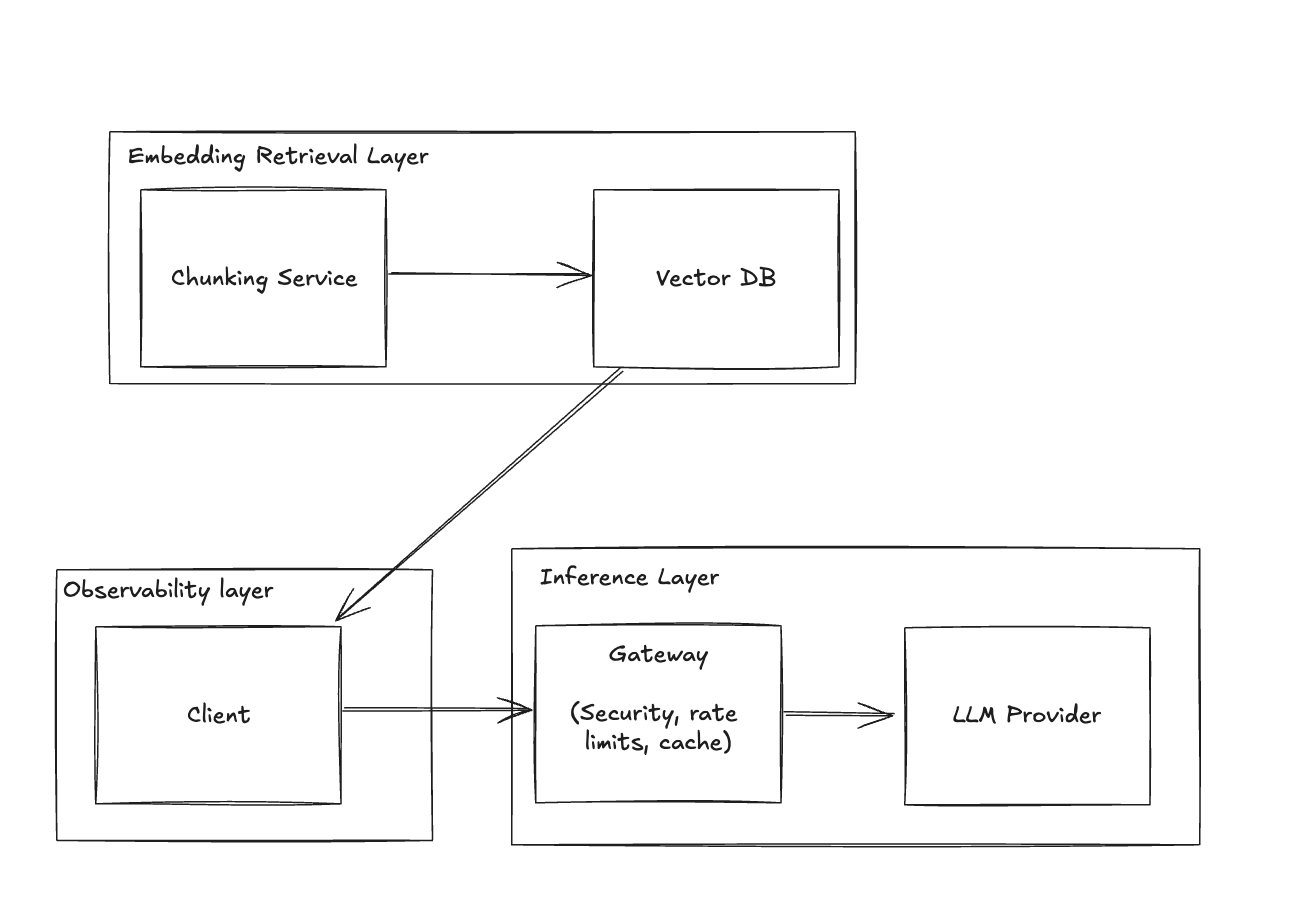
Solution: Implement a Gateway Layer
- Utilize Helicone Gateway.
- Introduce caching mechanisms and rate limiting.
Benefit:
- Improved performance and reduced latency.
- Controlled costs through efficient API management.
Stage 5: Enhancing with Tools Integration
Employees request additional functionalities, such as actioning emails directly through the chatbot.
Challenge:
- The chatbot can provide information but lacks interactivity.
- Need to perform operations like marking emails as read or scheduling.
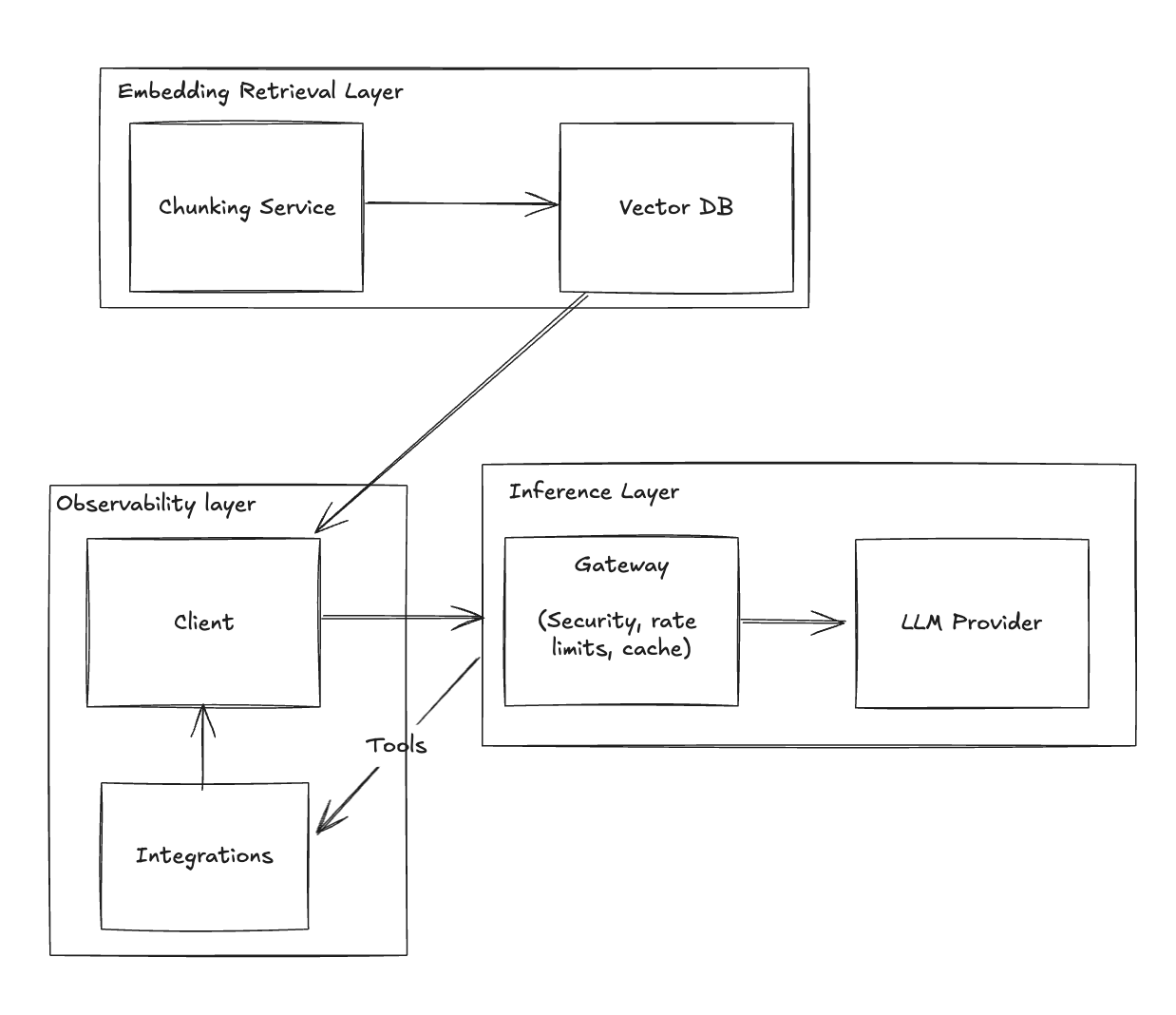
Solution: Incorporate Tools
- Integrate APIs for email management and calendar functions.
- Enable the chatbot to execute actions on behalf of the user.
Benefit:
- Increased productivity with interactive features.
- A more versatile and helpful chatbot.
Stage 6: Managing Prompts Effectively
As the chatbot evolves, maintaining and updating prompts becomes complex.
Challenge:
- Difficulty in tracking prompt versions.
- Inconsistent responses due to unmanaged prompt changes.
Solution: Implement Prompt Management
- Use Helicone Prompting.
- Version control for prompts and systematic testing.
Benefit:
- Consistent and reliable chatbot behavior.
- Ability to experiment and improve prompts efficiently.
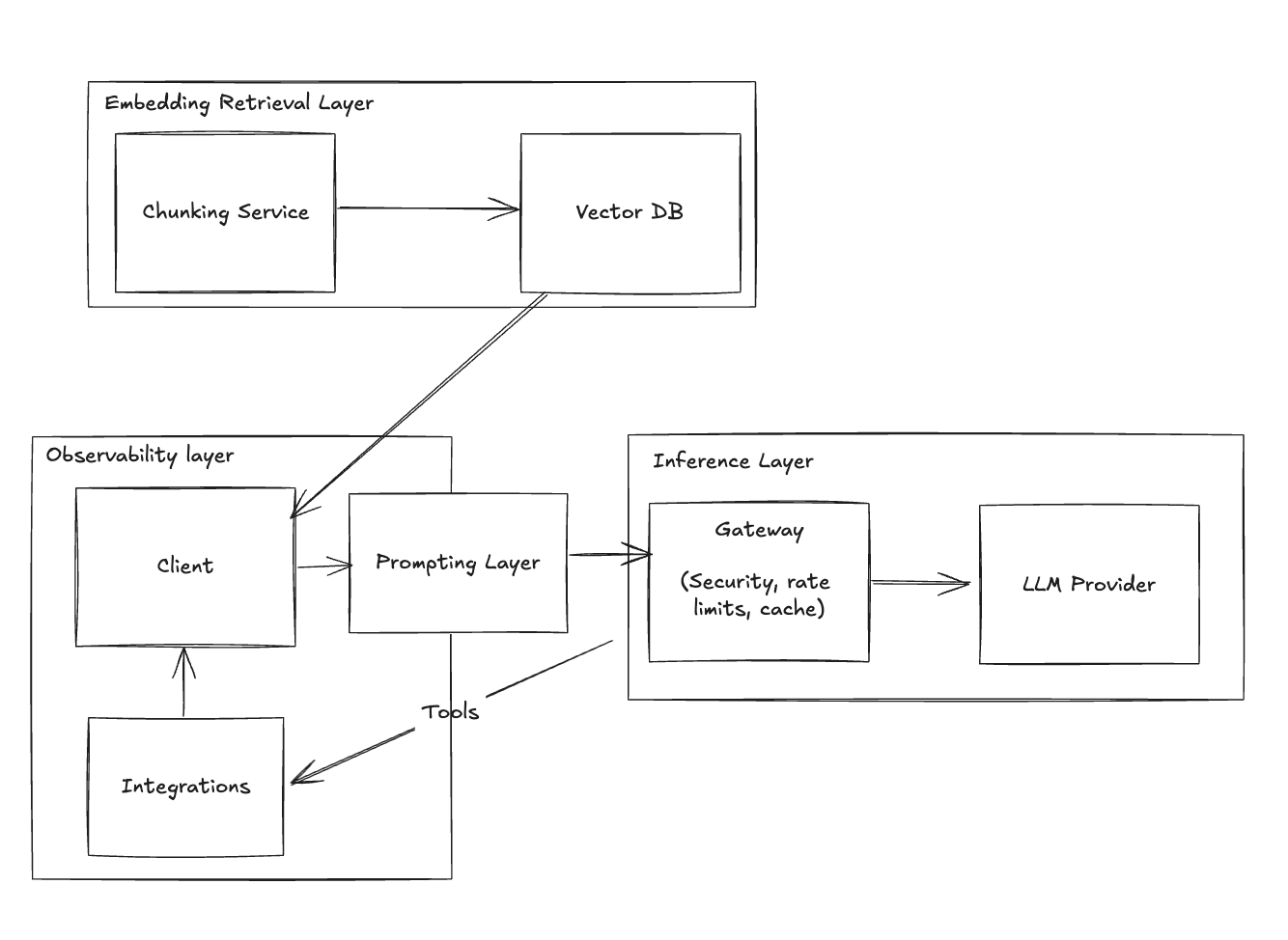
Stage 7: Introducing Agents for Complexity
Some tasks require the chatbot to make decisions and perform multiple steps autonomously.
Challenge:
- Linear prompts are insufficient for complex, multi-step tasks.
- Need for reasoning and dynamic decision-making.
Solution: Integrate Agents
- Utilize frameworks like AutoGPT or CrewAI.
- Enable the chatbot to plan and execute sequences of actions.
Benefit:
- Enhanced capabilities for complex operations.
- A more intelligent and autonomous chatbot.
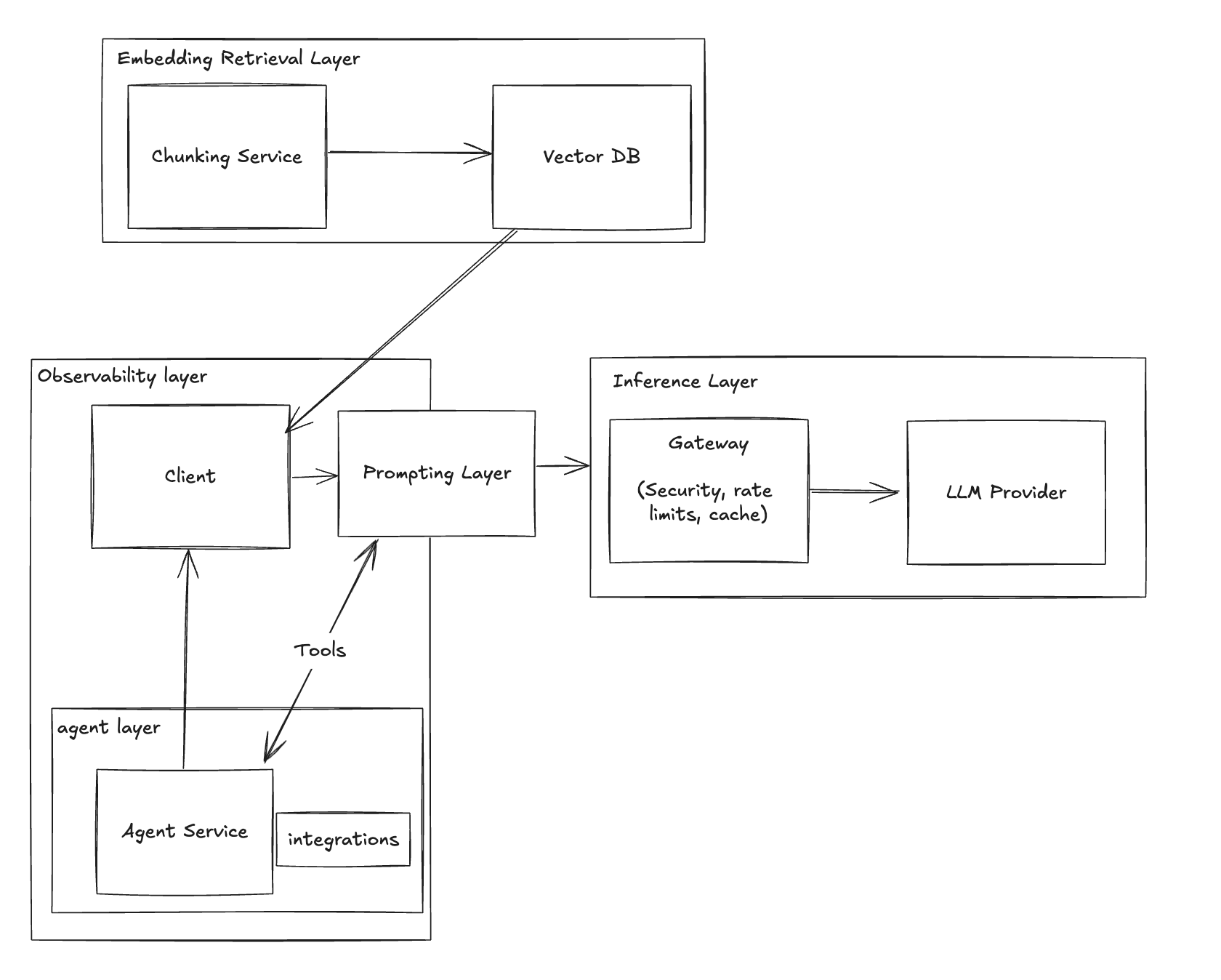
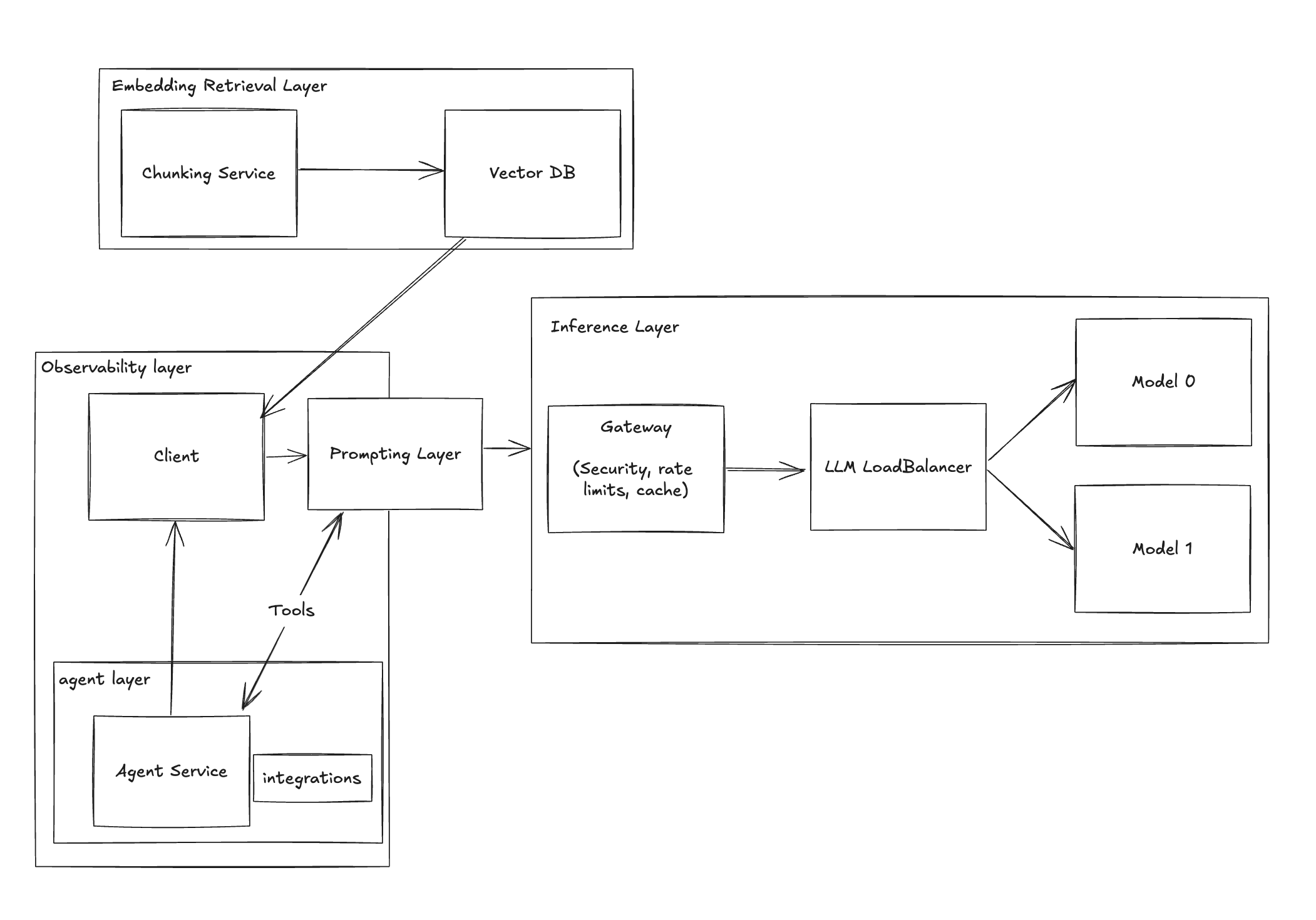
Stage 8: Balancing with Multiple Models
Different tasks demand different models for optimal performance and cost-effectiveness.
Challenge:
- Single model usage is limiting and may not be cost-efficient.
- Need to select models based on task requirements.
Solution: Implement a Model Load Balancer
- Use tools like Martian or LiteLLM.
- Dynamically route requests to the most suitable model.
Benefit:
- Improved performance tailored to task complexity.
- Cost savings by utilizing models judiciously.
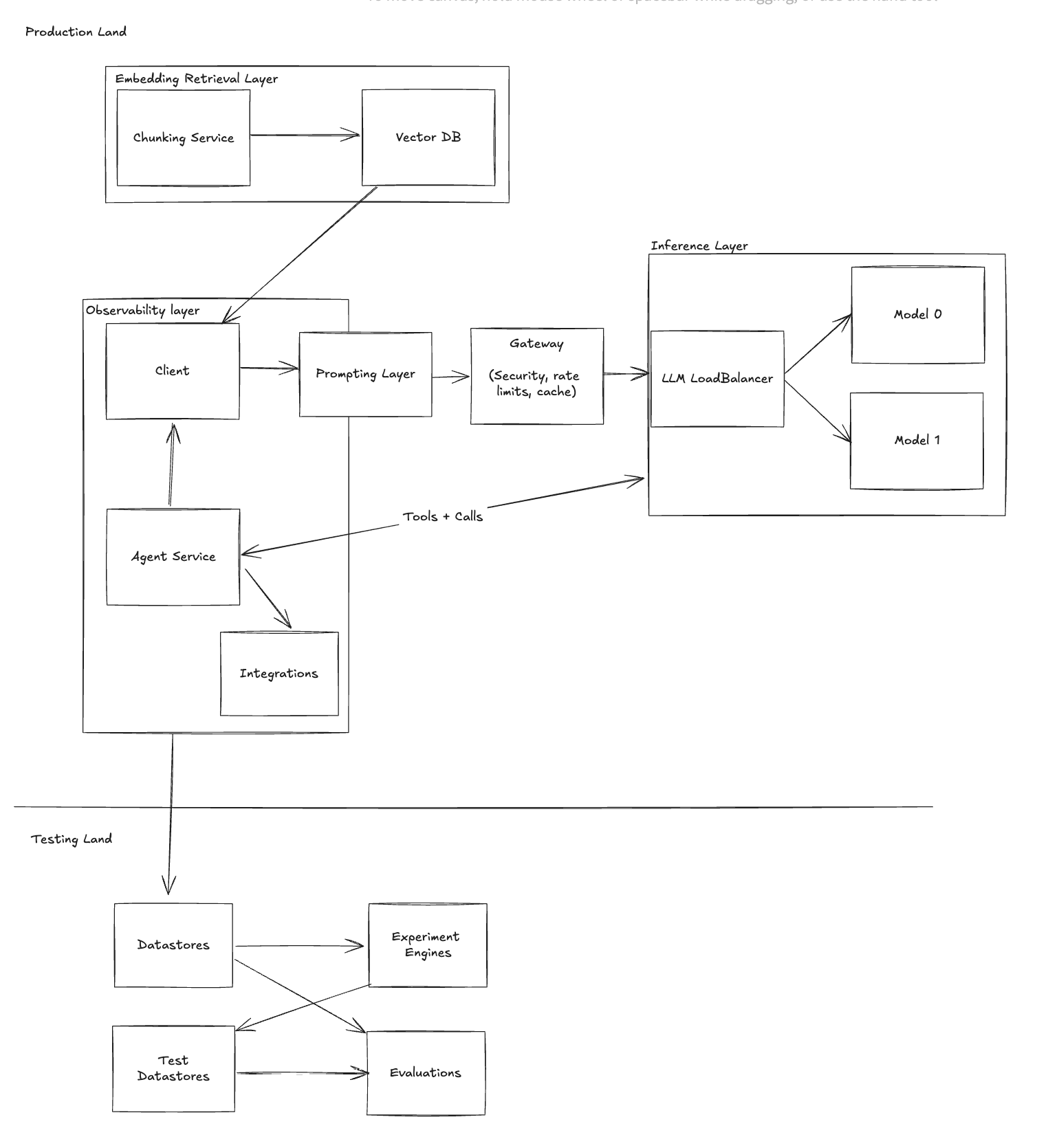
Stage 9: Testing and Experimentation
Continuous improvement requires systematic testing and feedback.
Challenge:
- Lack of a framework for A/B testing and evaluations.
- Difficult to measure the impact of changes.
Solution: Implement Testing & Experimentation Layer
- Adopt platforms like Helicone Experiments.
- Use evaluators like PromptFoo and Lastmile.
Benefit:
- Data-driven decisions for improvements.
- Enhanced chatbot performance through iterative testing.
Stage 10: Fine-Tuning for Specialization
To meet specific company needs, customizing models becomes necessary.
Challenge:
- General models may not align perfectly with domain-specific requirements.
- Potential for improved performance and reduced costs.
Solution: Fine-Tune Models
- Utilize services like OpenPipe or Autonomi.
- Train models on proprietary data for better alignment.
Benefit:
- Tailored responses with higher accuracy.
- Cost optimization through efficient model usage.
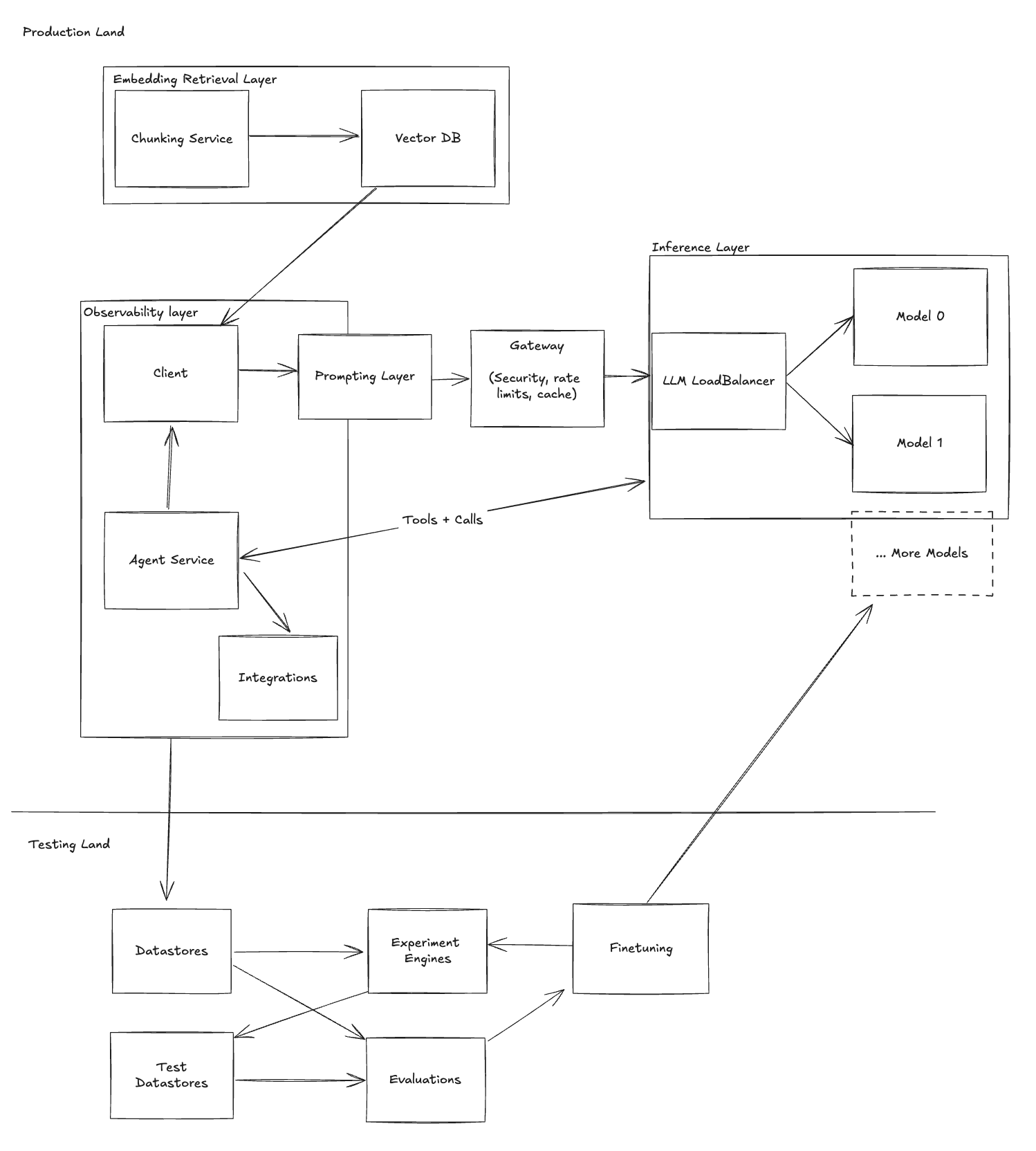
Embracing the LLM Stack: The Comprehensive Solution
Through these stages, Alex realizes that building a production-grade chatbot isn’t about patchwork solutions but adopting a structured approach—the LLM Stack.
Key Components of the LLM Stack:
- Observability Layer: Monitoring and insights to optimize performance.
- Inference Layer: Efficient management of models and providers.
- Testing & Experimentation Layer: Framework for continuous improvement.
- Prompt Management: Organized approach to prompt evolution.
- Agents and Tools: Enhanced functionality and interactivity.
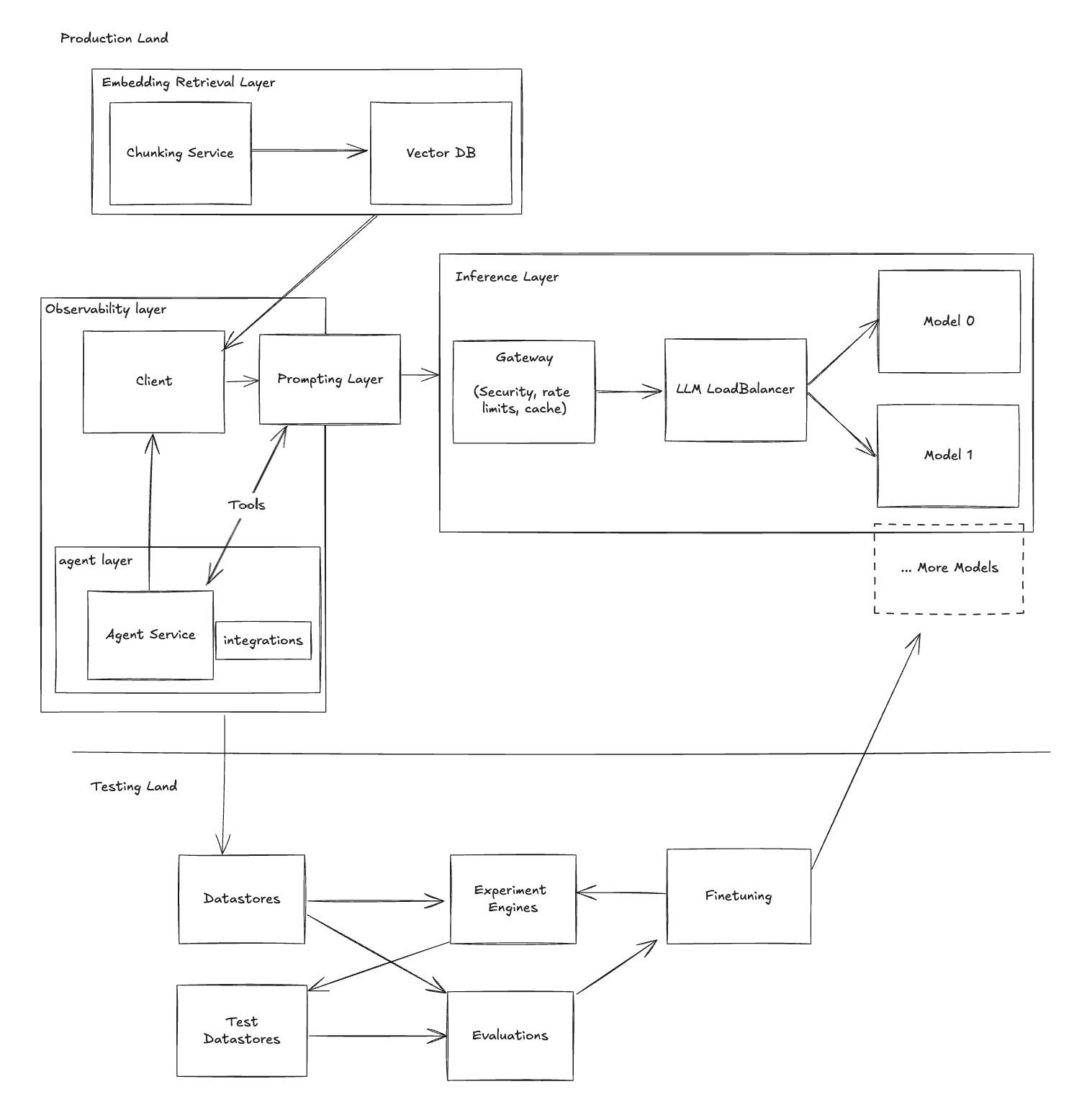
Helicone: Your Partner in LLM Excellence
At the heart of the LLM Stack, Helicone plays a pivotal role:
- Observability: Provides real-time analytics and logging.
- Gateway Services: Manages model integrations and API efficiency.
- Prompt Management: Offers tools for prompt versioning and tracking.
- Experimentation: Facilitates testing and evaluation for better outcomes.
Why Choose Helicone?
- Scalability: Designed to grow with your application’s needs.
- Efficiency: Streamlines processes, saving time and resources.
- Insights: Empowers you with data-driven decision-making.
By integrating Helicone, developers like Alex can focus on innovation rather than infrastructure, accelerating the journey to a robust, production-ready application.
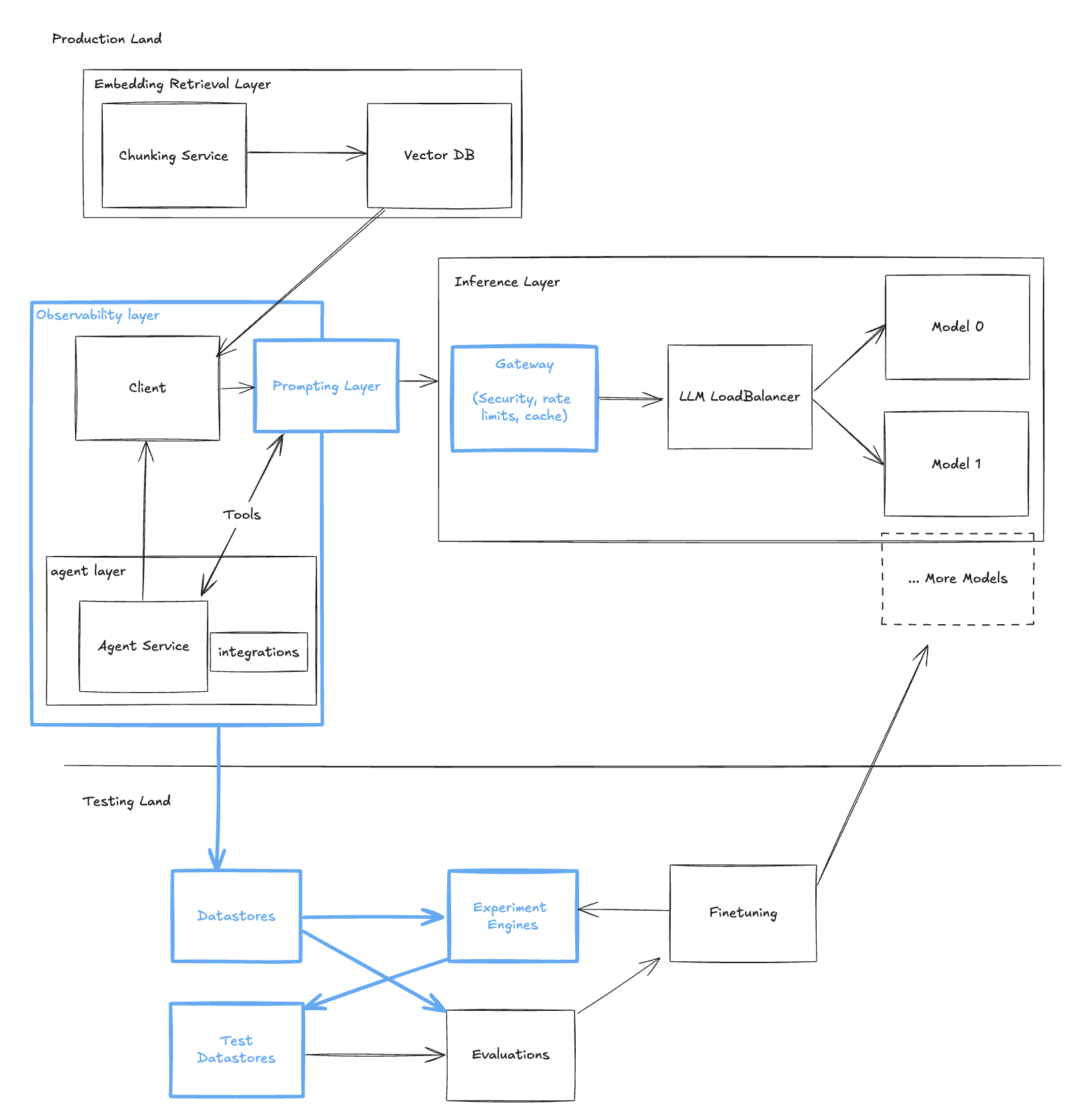
Conclusion: From Challenges to Mastery
Alex’s journey reflects the path many developers face when venturing into LLM applications. Initial simplicity gives way to complex challenges that require thoughtful solutions.
Key Takeaways:
- Adaptability: Embrace changes and new tools as your application evolves.
- Structured Approach: Leverage the LLM Stack for a comprehensive solution.
- Continuous Learning: Stay informed about emerging technologies and best practices.
Are you ready to transform your LLM application from a simple idea to a powerful tool? Embrace the LLM Stack and let Helicone guide you toward excellence.
Note: This article highlights components and tools that can enhance your LLM application. Choose solutions that align with your specific needs and objectives.